Glue
AWS Serverless Data Catalog & ETL Service

ETL Terms
- Meta Data : 데이터의 위치, 파일 형식, 압축 유형, 레코드 크기, 레코드 수, 컬럼 타입
- Data Catalog : 메타 데이터 저장소, 메타 데이터를 이용하여 보통의 테이블처럼 접근
- Crawling : 정형, 비정형, 반정형 소스 데이터로부터 Data Catalog 생성하는 작업
- ETL : 추출 (Extract), 변환 (Transform), 적재 (Load) 작업 – 실제 분석의 전단계
- Database & Table : 메타데이터를 table 형태로 저장한 객체 및 저장소
- Job : Crawling 또는 ETL 실행 작업
- Workflow : 연속적인 Job 의 묶음
Glue: Data Catalog – Crawler

주요 기능
- Built-in classifiers
- 파일 타입 파악
- 스키마 추출
- 파티션 탐지
- Custom classifiers
- Grok for ease of use
- On-Demand 또는 Scheduled 방식으로 실행
Glue: Data Catalog - 스키마 및 파티션 탐지

Glue: ETL - Job 스크립트 작성과 실행
- 서버리스 데이터 변환작업
- Apache Spark 기반
- 클릭 몇 번으로 생성되는 ETL code
- 수정 / 추가가 가능한 PySpark과 Scala 코드
- 반복 일정과 이벤트에 따른 Job 스케줄링
- Zeppelin, PyCharm 등 익숙한 환경에서 수정,디버그, 테스트가 가능하도록 Dev Endpoint 제공
- Sample ETL Codes
# Copyright 2016-2020 Amazon.com, Inc. or its affiliates. All Rights Reserved.
# SPDX-License-Identifier: MIT-0
from awsglue.transforms import *
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
sc = SparkContext()
glueContext = GlueContext(sc)
job = Job(glueContext)
# Please update the values in the options to connect to your own data source
options = {
"sfDatabase":"snowflake_sample_data",
"sfSchema":"PUBLIC",
"sfWarehouse" : "WORKSHOP_123",
"dbtable" : "lineitem",
"secretId" : "my-secret", # optional
"className" : "net.snowflake.spark.snowflake"
}
datasource = glueContext.create_dynamic_frame_from_options(
connection_type = "custom.spark", # for marketplace workflow, use marketplace.spark
connection_options = options,
transformation_ctx = "datasource")
datasource.show()
## Write to data target
glueContext.write_dynamic_frame.from_options(frame = datasource,
connection_type = "custom.spark",
connection_options = options)
job.commit()
AWS Glue ETL - Job 스케줄링과 모니터링
- 이벤트 기반 Job을 실행 가능하며, 여러 Job 사이에 의존성을 설정이 가능
- 각기 다른 조직에서 업무 연계와 Job의 재사용이 용이
- 다양한 Job 트리거 방법들
- 스케줄 기반 : 예) 특정 시간, 특정 일
- 이벤트 기반 : 예) Job 종료 / 실패 / 중단 / AWS Lambda
- On-demand
- Amazon CloudWatch를 통해 로그와 경고 확인 가능

AWS Glue 활용 패턴 - 데이터 웨어하우스로 ETL 작업
- Stream data, logs파일 다운로드/수집
- Job 실행 - ETL
- (필요 시) 관계되는 비교/부가 정보 dataset 활용
- 완료된 data를 data warehouse 에 전달
- 보고서 생성

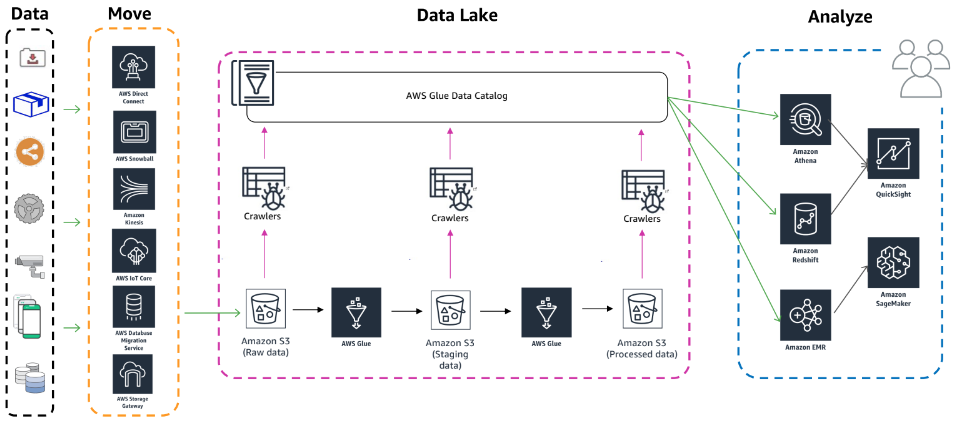
AWS Glue 활용 패턴 - 데이터 레이크
AWS Glue Studio
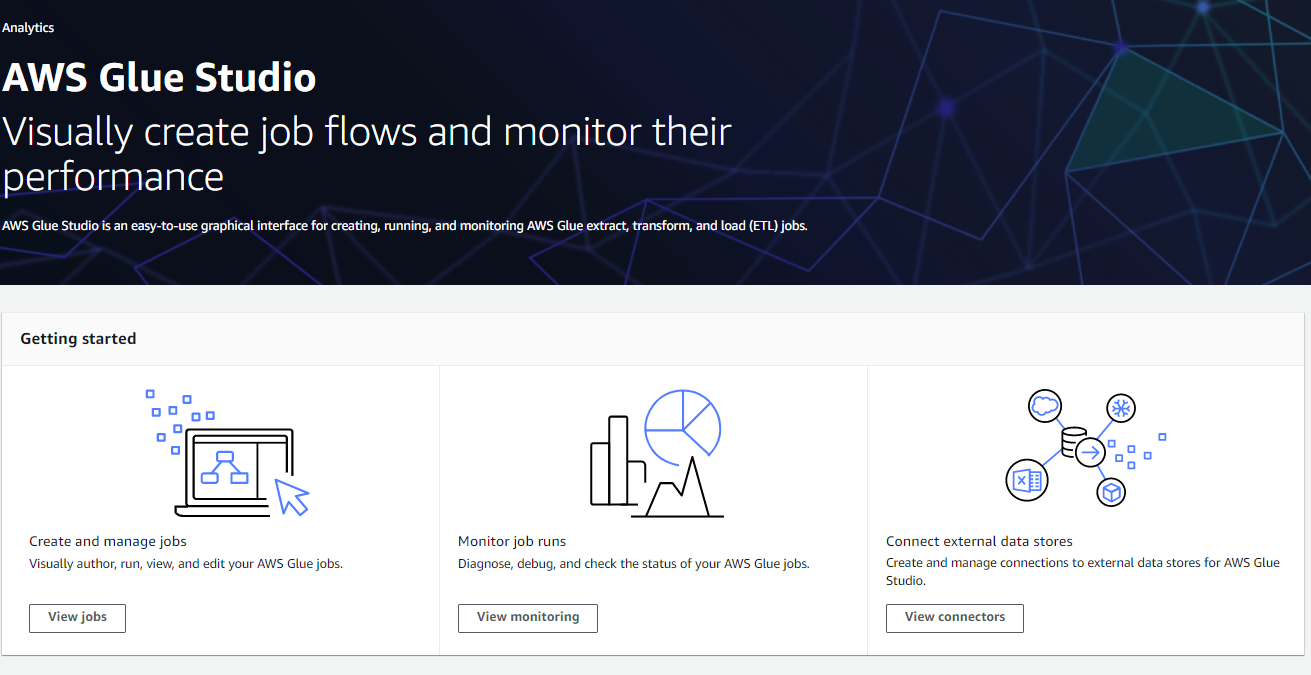
AWS Glue Studio는 AWS Glue에서 추출, 변환, 로드 작업을 쉽게 생성, 실행, 모니터링 할 수 있게 해주는 새로운 그래픽 인터페이스입니다. 데이터 변환 워크플로를 시각적으로 구성하고 AWS Glue의 Apache Spark 기반 서버리스 ETL 엔진에서 원활하게 실행할 수 있습니다. 작업의 각 단계에서 스키마 및 데이터 결과를 검사할 수 있습니다.
출처: https://docs.aws.amazon.com/ko_kr/glue/latest/ug/what-is-glue-studio.html
AWS Glue Studio란 무엇인가요? - AWS Glue Studio
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다. AWS Glue Studio란 무엇인가요? AWS Glue Studio는 AWS Glue에서 추출, 변환, 로드 작업
docs.aws.amazon.com
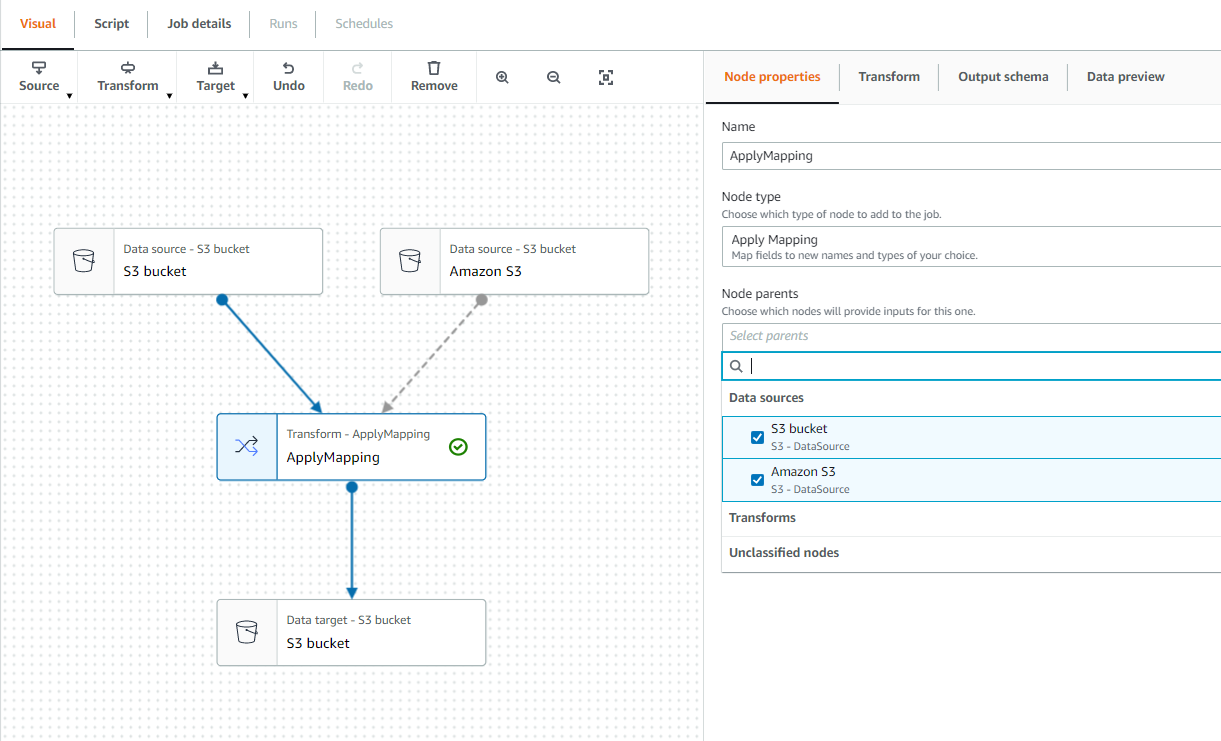
Glue Studio - UI



Glue Studio - Source

Glue Studio - Transform
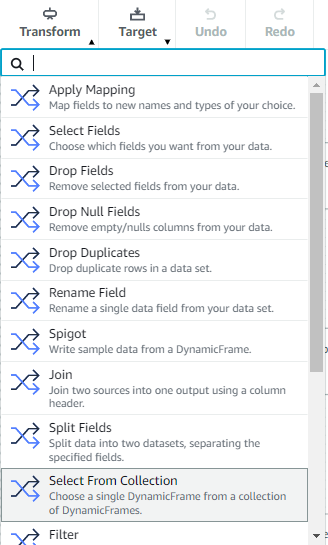
- ApplyMapping: 소스와 대상 사이의 데이터 속성 매핑 (type 매핑, 키 삭제, 키 이름 변경)
- SelectFields: 유지하려는 데이터 속성 키 선택
- DropFields: 삭제하려는 데이터 속성 키 선택
- RenameField: 단일한 데이터 속성 이름 변경
- Spigot: S3 에 데이터의 샘플을 쓰기
- Join: 두 데이터셋 사이에 조인
- SplitFields: 데이터 속성 키를 2개의 DynamicFrames으로 분할
- FillMissingValues: 누락값 채우기
- Filter: 데이터셋을 필터 조건에 따라 두개의 데이터셋으로 분할
- DropNullFields: 컬럼에 있는 모든 값이 null 이면 컬럼 삭제
- SQL: SparkSQL 코드 입력, 출력은 단일한 DynamicFrame
- Aggregate: 선택한 필드와 행에 대해 계산(예: 평균, 합계, 최소, 최대)을 수행, 계산된 값으로 새 필드 생성
- Custom transform: 사용자 정의형 변환, 출력은 DynamicFrame 의 Collection
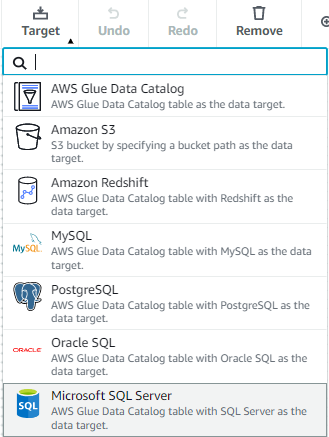
Glue Studio - Target
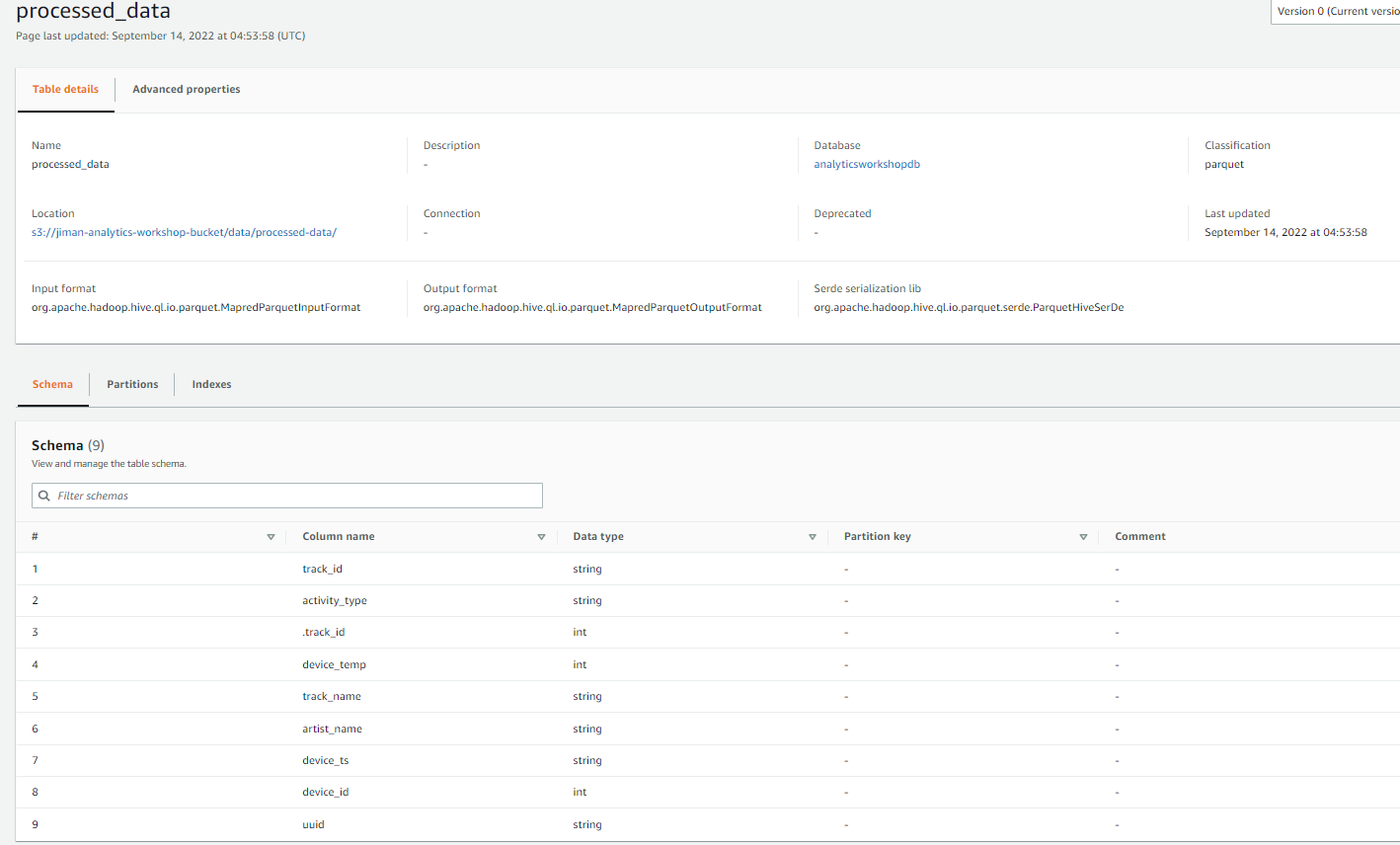
Glue - Tables

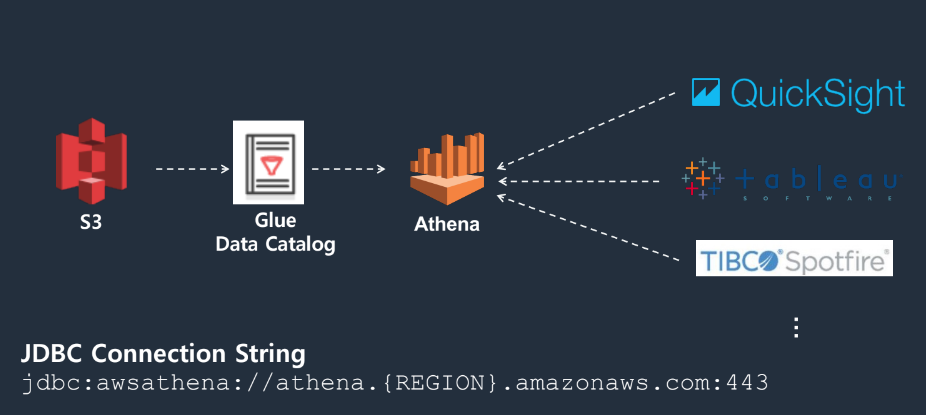
Athena
- Serverless - 인프라 관리 불필요, 자동 확장
- S3에서 직접 Query 실행
- Query를 위해 Data Loading / ETL 불필요
- Schema on Read
- 스캔된 데이터 만큼 과금
- 보안 - IAM을 통한 인증 / 암호화 : 테이블, Query문, Write Output
- AWS Glue 데이터 카탈로그와 통합
SELECT artist_name,
count(artist_name) AS count
FROM processed_data
GROUP BY artist_name
ORDER BY count desc
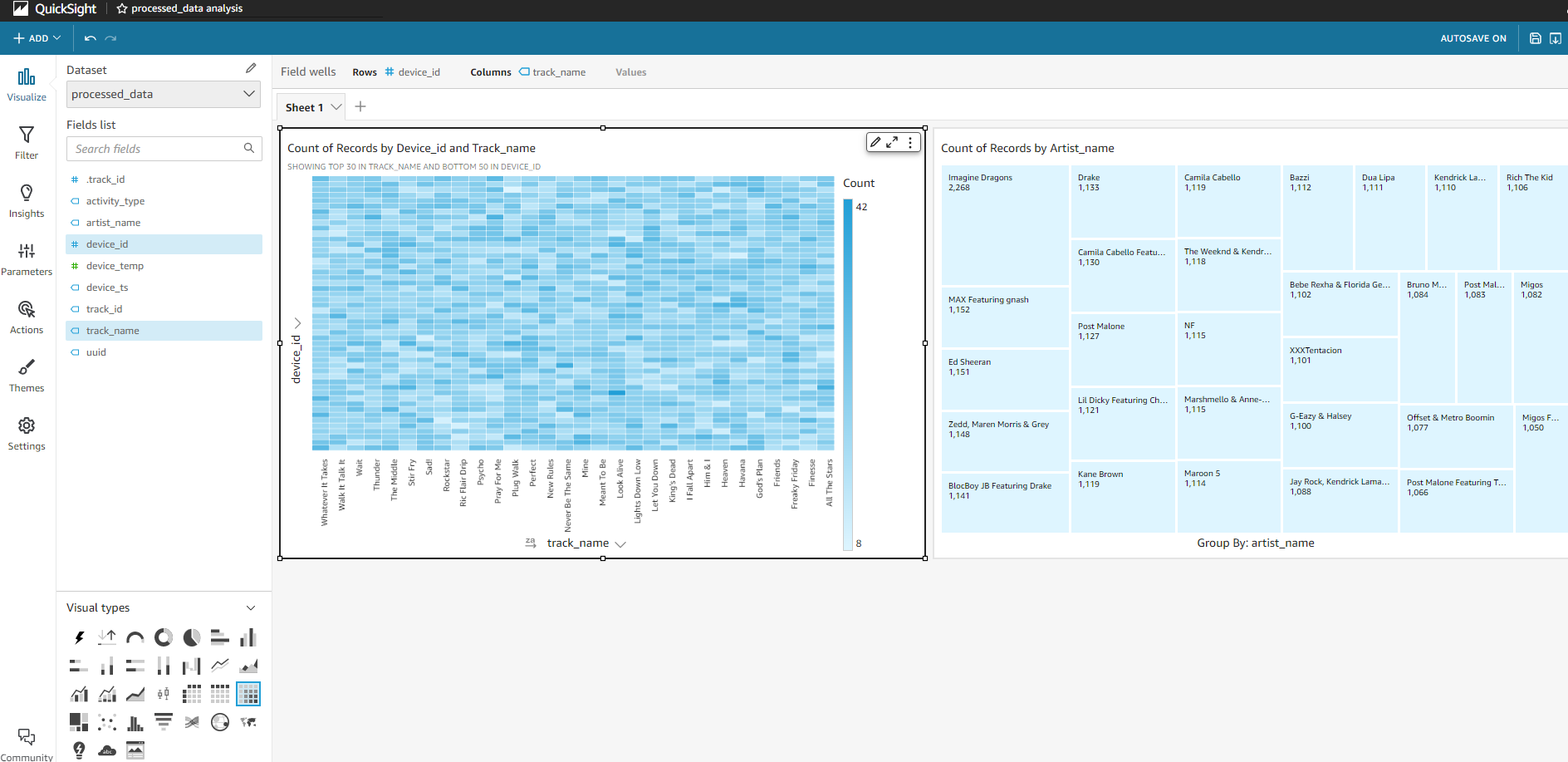
QuickSight
직관적인 시각화 및 AutoGraph
- 데이터 유형 자동 감지
- 최적의 쿼리 생성
- 다양한 graph 타입 제공
- 빠른 결과
머신러닝 기반의 예측 서비스 제공
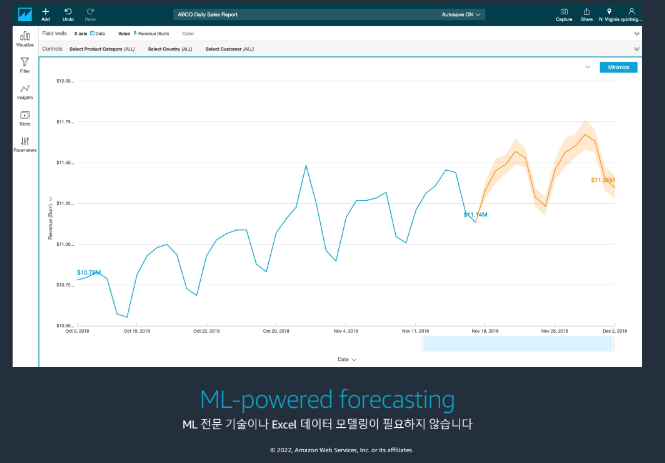
Redshift
OLTP/OLAP/Data Lake
- OLTP (Online Transaction Processing)
어플리케이션에서 지속성을 제공하면서, 대량으로 빠르게 온라인 트랜잭션을 처리하는 특성 (INSERT, UPDATE, DELETE)
예: Aurora, MySQL, PostgreSQL - OLAP (Online Analytical Processing) - DW
상대적으로 적은 양의 트랜잭션으로 데이터 중심의 의사 결정을 위하여 대규모 과거 데이터를 집계하는 등의 복잡한 쿼리로 구성
예: e.g. Amazon Redshift, Greenplum - Data Lake
모든 데이터를 저장할 수 있는 용량을 가지고, 저렴한 비용으로 수집, 저장할 수 있는 통합 아키텍처 패러다임. DW를 보완
예: S3 data lake
Redshift instance types
Amazon Redshift RA3 (current generation)
• Amazon Redshift Managed Storage (RMS)
• SSD (Hot Data) + Amazon S3 (Cold Data - 자동확장)
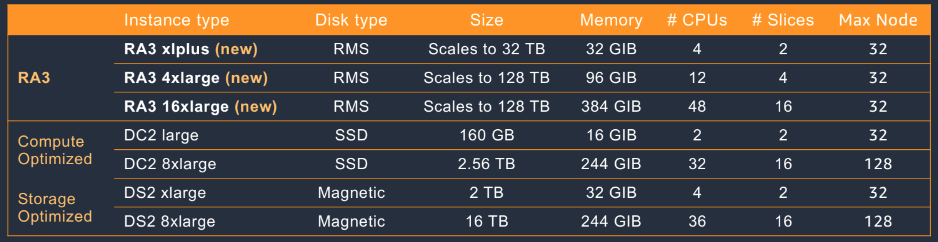
AQUA (Advanced Query Accelerator)
- 새로운 하드웨어 기반 가속 캐시를 통해 추가 비용 없이 타 클라우드 DW 보다 10 배 빠르게 질의 실행
- AWS 가 설계한 Processor 를 이용하여 압축/암호하/필터링/집계 가속화
- RA3 에서 지원

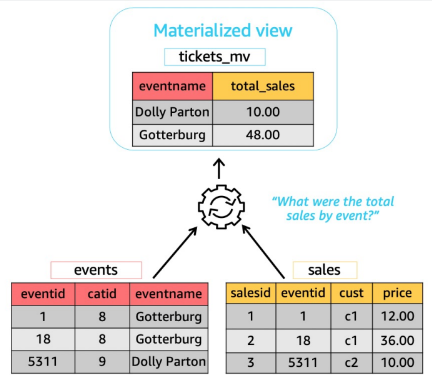
Redshift Materialized Views (MVIEW)
Speed-up queries by orders of magnitude
• Joins, filters, aggregations, and projections
Simplify and accelerate ETL/BI pipelines
• Incremental refresh
• User triggered maintenance
Easier and faster migration to Amazon Redshift
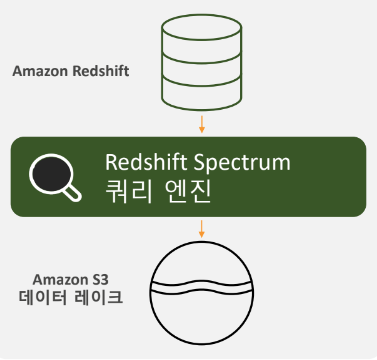
Amazon Redshift Spectrum
Redshift Spectrum - 데이터 레이크와의 통합
Amazon Redshift에서 S3데이터에 대한 쿼리
• 다양한 포멧 지원
(CSV, ORC, Gro, Avro, Parquet)
• 빠른 쿼리 성능
• Compute과 Storage 에 대한 별도의 용량 관리
• On demand, 쿼리당 스켄 데이터에
기준한 비용 (TB 당 $5)
Workshop Studio
catalog.us-east-1.prod.workshops.aws
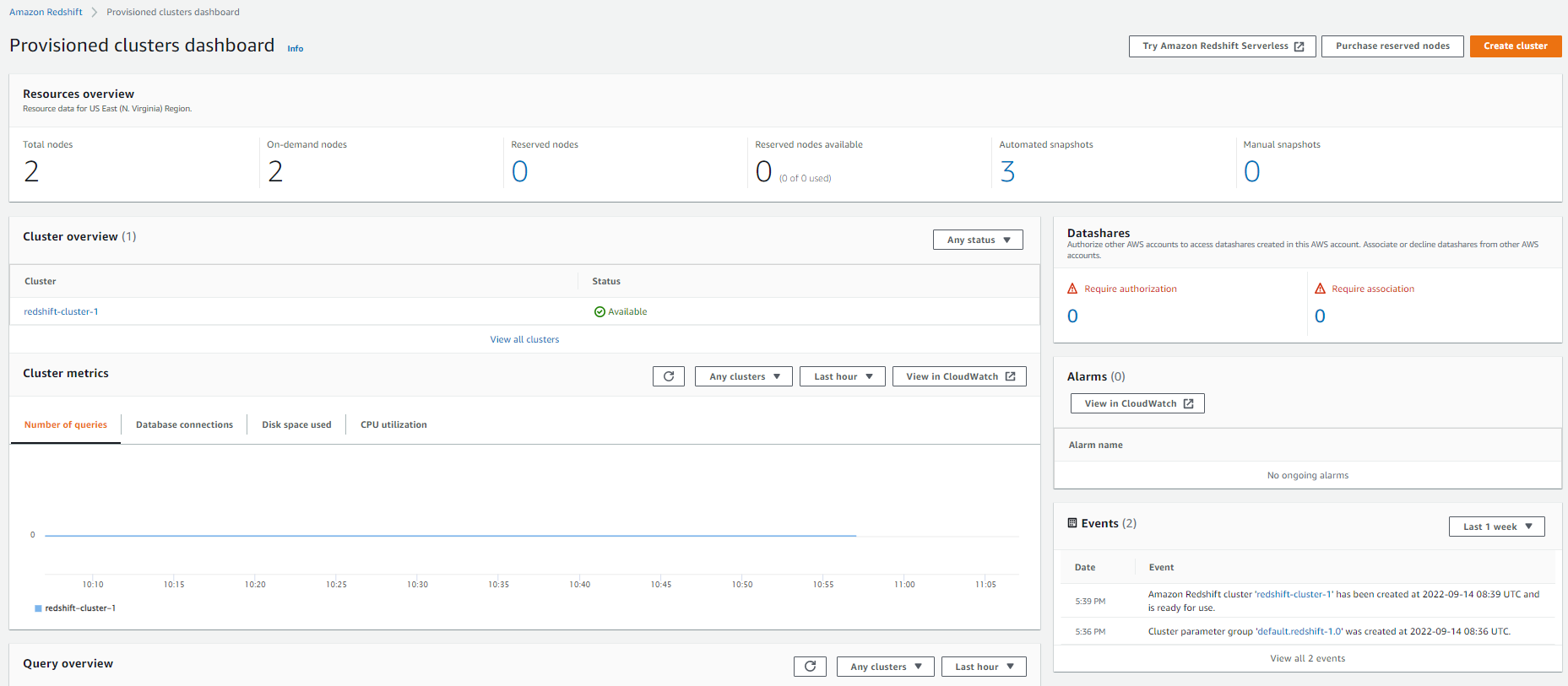
Redshift Serverless

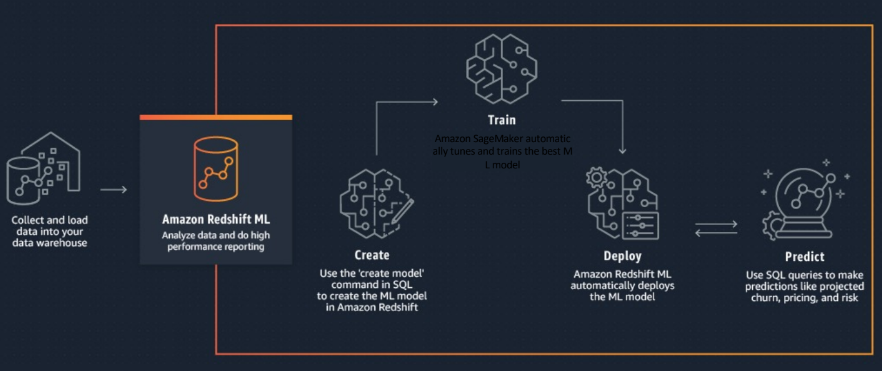
Amazon Redshift ML
Kinesis
Workshop Studio
catalog.us-east-1.prod.workshops.aws
Kinesis Data streams

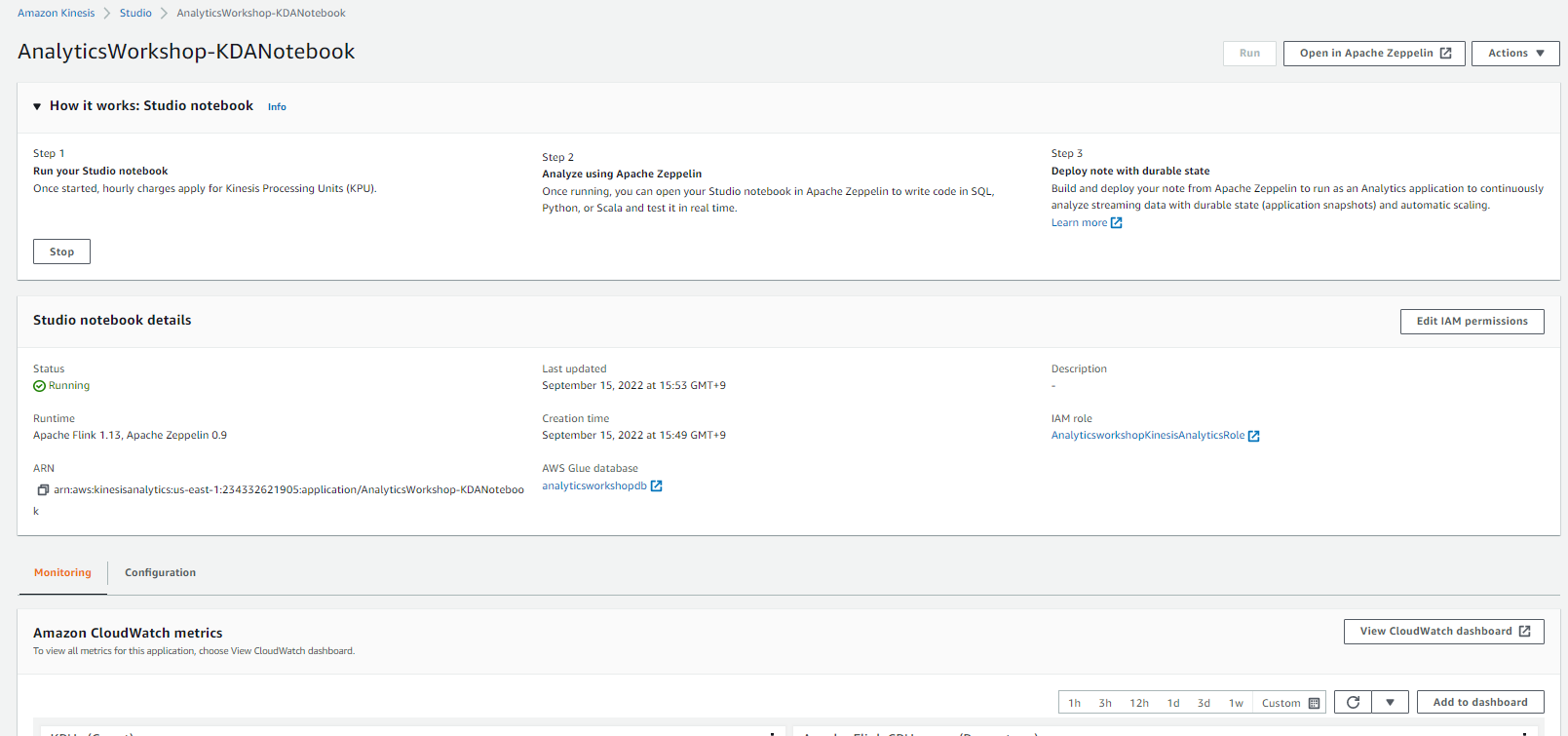
Analytics Streaming Application Studio Notebook
- Kinesis Application Notebook은 AWS Glue에서 데이터 원본에 대한 정보를 가져옵니다
- 분석 애플리케이션 노트북은 Kinesis Data Stream의 스트리밍 데이터를 처리할 수 있으며, 실시간으로 인사이트을 얻기 위해 SQL 분석 쿼리를 작성할 수 있습니다.
%flink.ssql(type=update)
SELECT * FROM raw_stream;
%flink.ssql(type=update)
SELECT activity_type, count(*) as activity_cnt FROM raw_stream group by activity_type;
'AWS' 카테고리의 다른 글
| aws lambda asynchronously 예약 동시성 0의 비동기처리 변경 (0) | 2023.06.26 |
|---|